Read the book here: situational-awareness.ai or find the full series as a 165-page PDF here.
I have summarised & highlighted the important concepts covered in the book for speed reading.
Chapter 1: From GPT-4 to AGI: Counting the OOMs
TL;DR
The author outright claims that “achieving AGI by 2027 is plausible”, which took me aback. However, the data points presented in this chapter convinced me of his argument.
GPT-2 to GPT-4 took us from ~preschooler to ~smart high-schooler abilities in 4 years. So, we should expect preschooler-to-high-schooler-sized-qualitative jump by 2027 by tracing the trend lines in three categories of scale ups:
- Compute (~0.5 OOMs/year)
- Algorithmic efficiencies (~0.5 OOMs/year)
- Unhobbling (from chatbots to agents)
Here are some of the figures used by the author to support his claim.
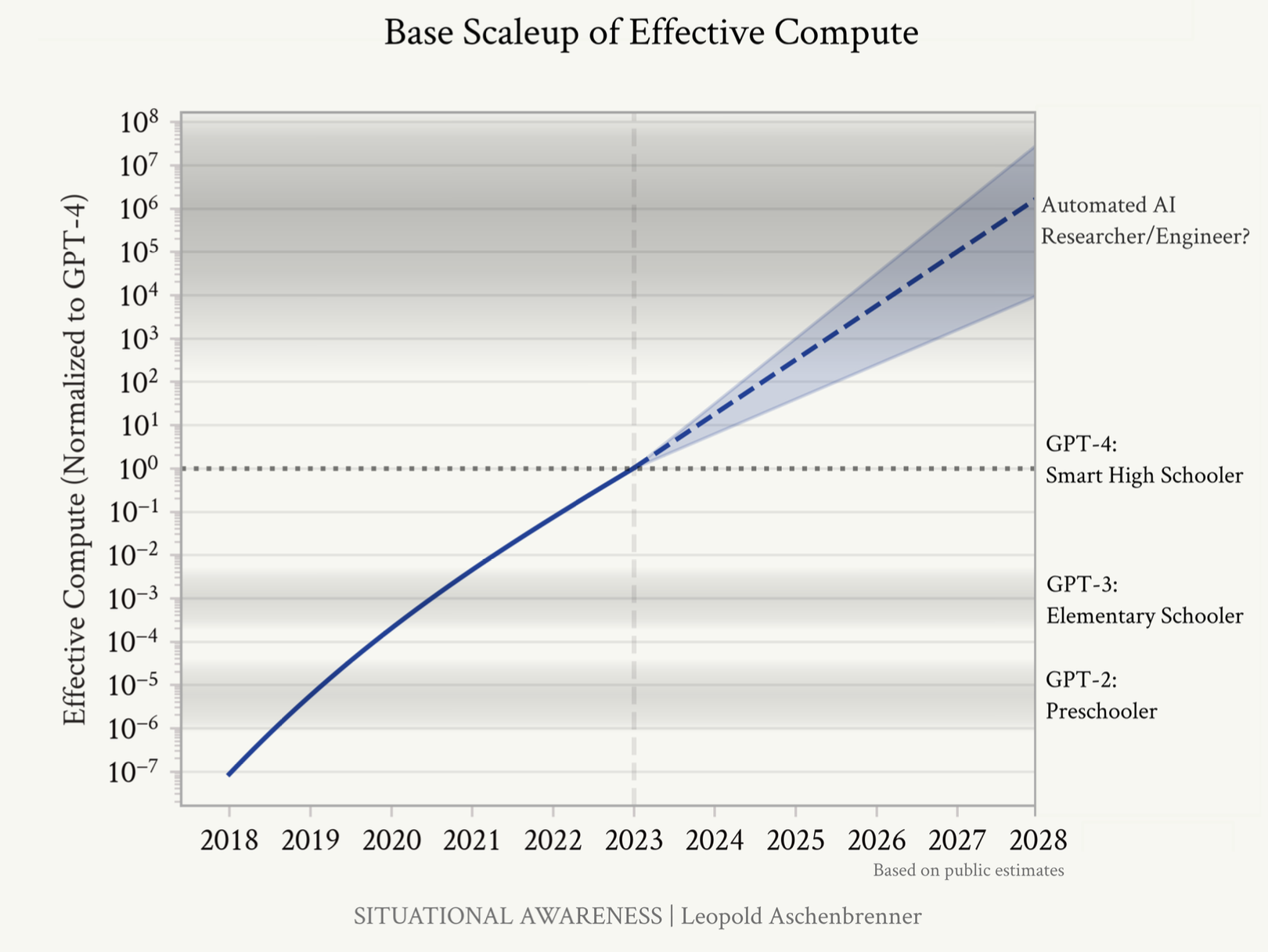 Figure: Rough estimates of past and future scaleup of effective compute (both physical compute and algorithmic efficiencies).
Figure: Rough estimates of past and future scaleup of effective compute (both physical compute and algorithmic efficiencies).
 Figure: Progress over just 4 years.
Figure: Progress over just 4 years.
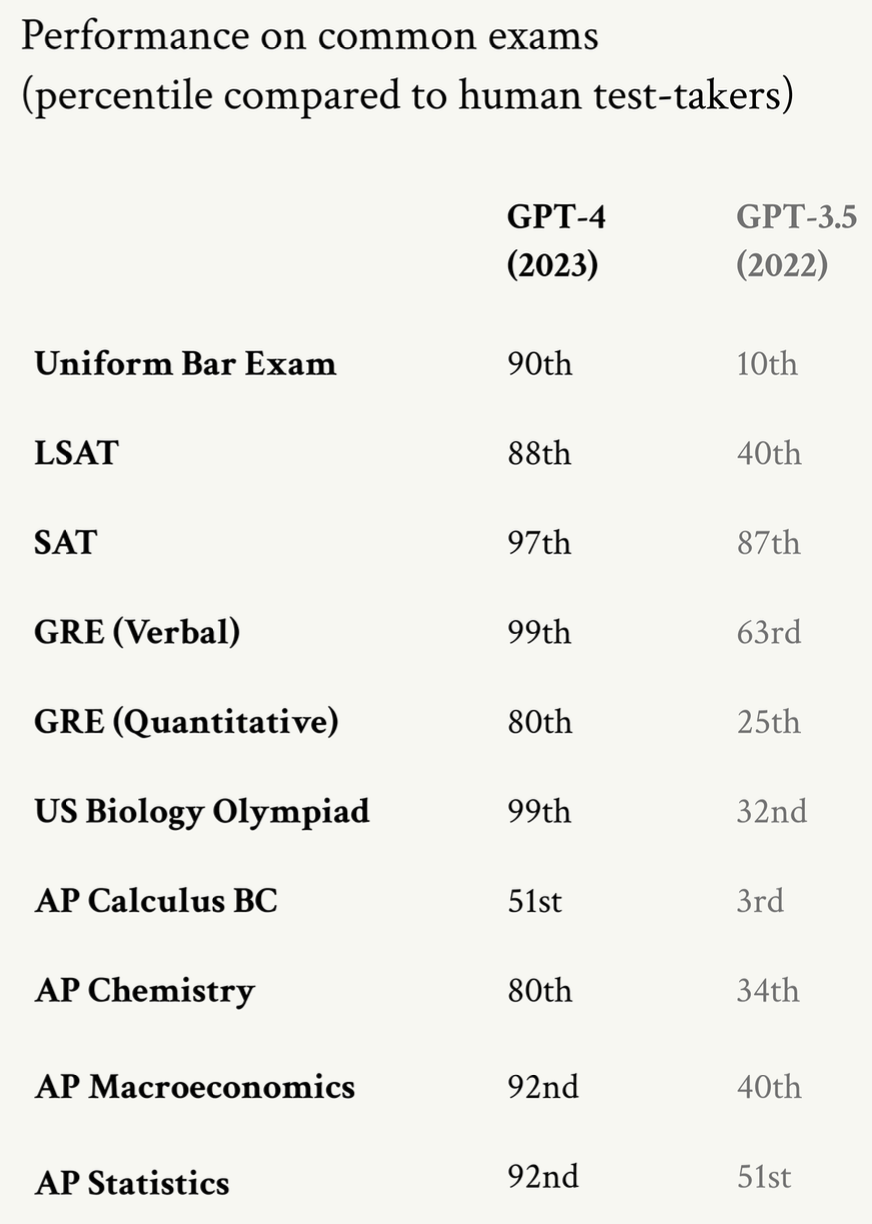 Figure: GPT-4 scores on standardized tests.
Figure: GPT-4 scores on standardized tests.
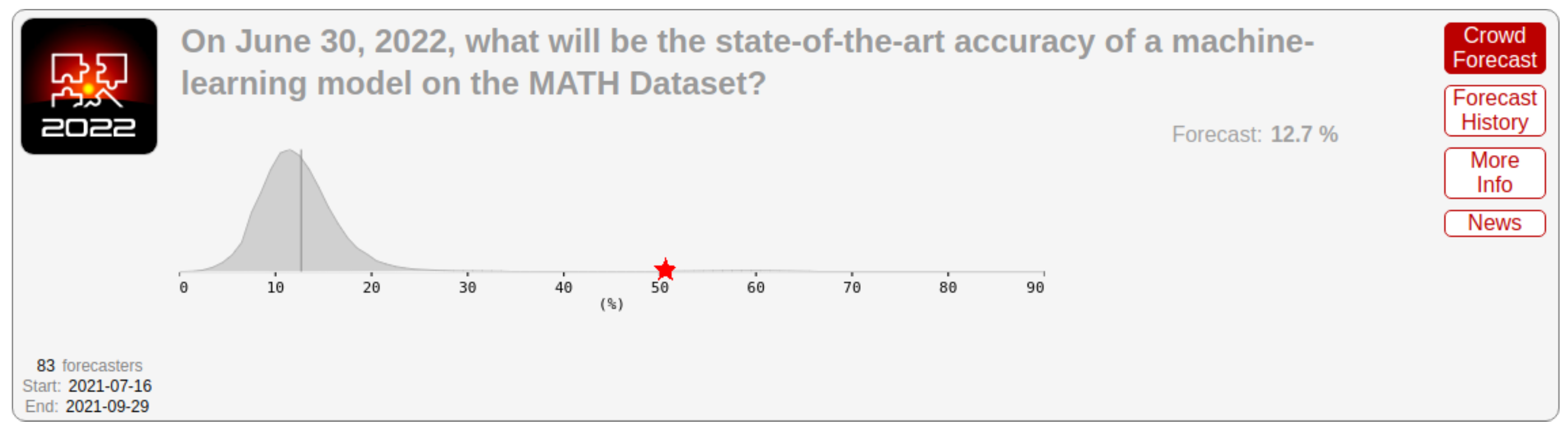 Figure: Gray: Professional forecasts, made in August 2021, for June 2022 performance on the MATH benchmark (difficult mathematics problems from high-school math competitions). Red star: actual state-of-the-art performance by June 2022, far exceeding even the upper range forecasters gave.
Figure: Gray: Professional forecasts, made in August 2021, for June 2022 performance on the MATH benchmark (difficult mathematics problems from high-school math competitions). Red star: actual state-of-the-art performance by June 2022, far exceeding even the upper range forecasters gave.
Compute
GPT-2 to GPT-4 roughly has training compute growth of ~4 OOMs (10,000x) in less than 4 years.
 Table: Estimates of compute in FLOP for GPT-2 to GPT-4 by Epoch AI.
Table: Estimates of compute in FLOP for GPT-2 to GPT-4 by Epoch AI.
GPT comparison
Compute time, Parameter count, Embedding Size, Context Window
Given, NVIDIA A100 has a throughput of for FP16 precision,
Year Model Est. Parameter Count Embedding Size Context Window Vocabulary Size Est. Compute†
(in FLOPs & TFLOPs)Est. training duration with GPUs Est transformer layers Est. Compute Growth Est. Parameter Growth 2018 GPT-1 117M 768 ~512 tokens GPT-2 Small 117M 768 1024 tokens 50257† GPT-2 Medium 345M 1024 1024 tokens 50257† GPT-2 Large 762M 1280 1024 tokens 50257† 2019 GPT-2 XL 1.5B 1600 1024 tokens 50257†
GPT-3 (Ada) ~350M 768 2048 tokens 50257† GPT-3 (Babbage) ~1.3B 1024 2048 tokens 50257† GPT-3 (Curie) ~6.7B 1600 2048 tokens 50257† 2020 GPT-3 (Davinci) 175B 12288 2048 tokens 100256†
96 + ~2 OOMs + ~2 OOMs 2023 GPT-4 (Varies) ~1-2 trillion params Upto 12288 8192 - 32768 tokens 100256†
+ ~1.5-2 OOMs + ~1 OOM GPT-4o-Mini 200019†
- *without factoring in memory bandwidth, latency, power efficiency, etc.
- †Sources:
Visual comparison
graph LR A[GPT Models] --> GPT1[GPT Original] GPT1 --> G1D[768 dimensions, 512 tokens] A --> GPT2[GPT-2] GPT2 --> G2S[Small: 768 dimensions, 1024 tokens] GPT2 --> G2M[Medium: 1024 dimensions, 1024 tokens] GPT2 --> G2L[Large: 1280 dimensions, 1024 tokens] GPT2 --> G2XL[XL: 1600 dimensions, 1024 tokens] A --> GPT3[GPT-3] GPT3 --> G3A[Ada: 768 dimensions, 2048 tokens] GPT3 --> G3B[Babbage: 1024 dimensions, 2048 tokens] GPT3 --> G3C[Curie: 1600 dimensions, 2048 tokens] GPT3 --> G3D[Davinci: 12288 dimensions, 2048 tokens] A --> GPT4[GPT-4] GPT4 --> G4V[Up to 12288 dimensions, 8192-32768 tokens]Pre-training dataset and cost
Link to original
Year Model Dataset (size) Cost (in terms of cloud compute) 2018 GPT-1 2019 GPT-2 2020 GPT-3 300 billion tokens†
(60% of original data of 499 billion tokens)~$4.6 million† 2023 GPT-4 *Sources:
 Source: Epoch AI
Source: Epoch AI
In a nut shell, GPT-2 to GPT-4 jump included 3.5-4 OOMs of compute gains over 4 years period (i.e., ~1 OOMs/year of compute efficiency).
Algorithmic efficiencies
There have been many tweaks and gains in architecture, data, training stack, etc, collectively called as algorithmic progress, which is probably a similarly important driver of progress along with compute. However, unlike compute, algorithmic progress do not get all the attention and are dramatically underrated.
Inference efficiency improved by nearly 3 OOMs (1000x) in less than 2 years.
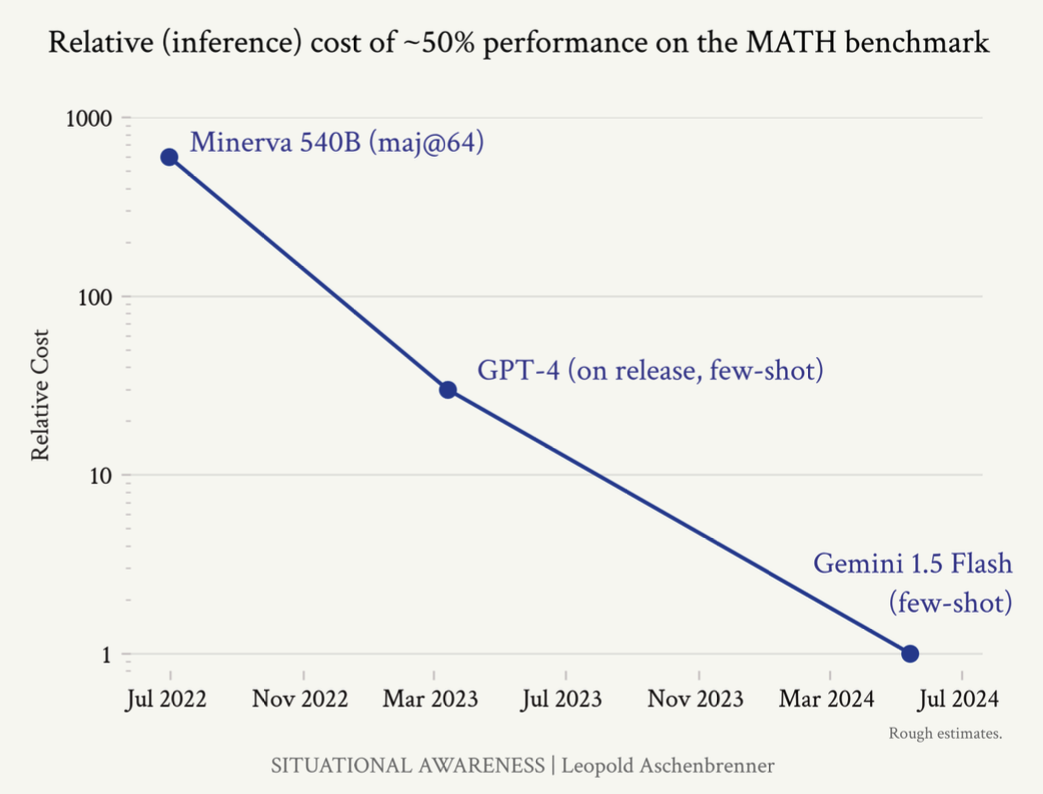 Figure: Rough estimate on relative inference cost of attaining ~50% MATH performance.
Figure: Rough estimate on relative inference cost of attaining ~50% MATH performance.
| Date | Model | Cost per 1M Input Tokens | Cost per 1M Output Tokens |
|---|---|---|---|
| N.A. Source | GPT-3 | $30.0 | $60.0 |
| Dec-2024 (Source) | GPT-4o* | $2.5 (12x reduction) | $10.0 (6x reduction) |
| *Cost further drops by half for Batch API. |
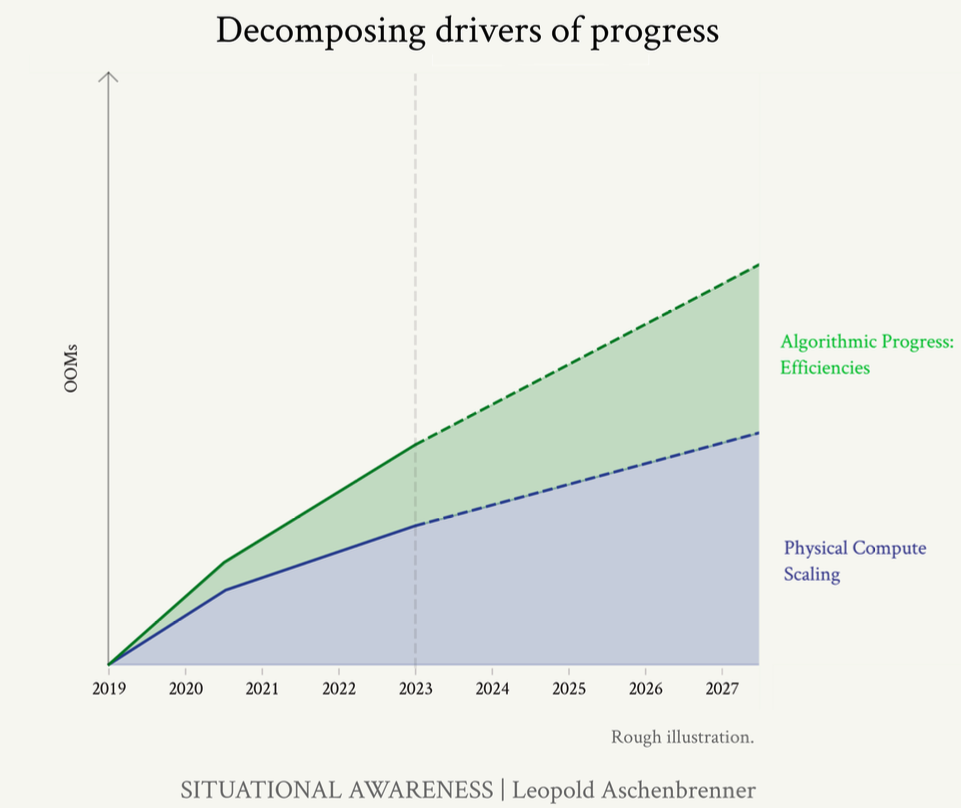 Figure: Decomposing progress: compute and algorithmic efficiencies. (Rough illustration)
Figure: Decomposing progress: compute and algorithmic efficiencies. (Rough illustration)
In a nut shell, GPT-2 to GPT-4 jump included 1-2 OOMs of algorithmic efficiency gains over 4 years period (i.e., ~0.5 OOMs/year of algorithmic efficiency).
Data wall
We’re running out of interent data.
Frontier models are already trained on much of the internet data. For e.g., Llama 3, was trained over 15T tokens. Common Crawl, dump of much of internet, used for LLM training, is >100T tokens raw, and a relatively simple deduplication leads to 30T tokens. For more specific domains like code, there are fewer tokens. For e.g., public github repos are estimated to be in low trillions of tokens.
After 16 epochs, repeating the data for pre-training returns extremely diminishing results.
That being said, all of the labs are rumoured to make massive bets on new algorithmic improvements/approaches to get around this.
What a modern LLM does during training is, essentially, very very quickly skim the textbook, the words just flying by, not spending much brain power on it. Just reading the same textbook over and over again might result in memorization, and not understanding. This is in contrast to how read a (say, math) textbook, where we read a couple of pages slowly; then digest it, ponder over it; discuss with our friends; try few practice problems; fail, try again in a different way, get some feedback, try again until we get it right; and so on, until, it “clicks”. So, there’s a “missing middle” between “pre-training” and “in-context learning”. When a human learns from a textbook, they’re able to distill their short-term memory/learnings into long-term memory/long-term skills with practice; however, we don’t have an equivalent way to distill in-context learning “back to the weights.” Synthetic data/self-play/RL/etc. are trying to fix that: let the model learn by itself, then think about it and practice what it learned, distilling that learning back into the weights.. One such example would be AlphaGo, which was initially trained to imitate learning on expert human Go games, and then by playing millions of games against itself.
In a nut shell, though we are hitting the data well, we will have unconver enough (near and long term) tricks to continue with our ~X OOMs/year progress in this space.
Unhobbling
Despite excellent raw capabilities, LLMs are much worse than they could be because they are hobbled, and it takes some algorithmic tweak (e.g., Chain-of-thought) to unlock much greater capabilities.
Key terminologies
| Term | Explanation | |
|---|---|---|
| OOM | Order of Magnitude. | 3x is 0.5 OOM 10x is 1 OOM (i.e., 1 order of magnitude). |
| FLOP | Floating Point Operation | |
| FLOPS | Floating Point Operation per Second |