GPT-3 dataset details†
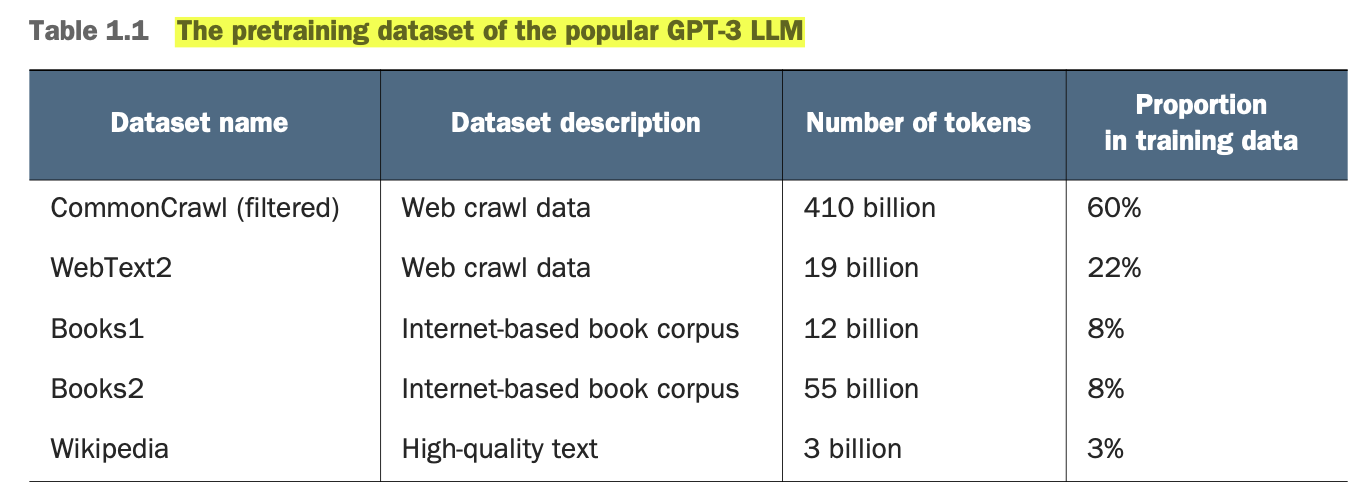
"Number of tokens" col total ~499 billion, but the model was trained only on 300 billion tokens (⇒ 60% of the original data).
- 410 billion tokens from CommonCrawl dataset requires ~570GB of storage (perhaps, not a lot 🤔).
- Later iterations of GPT-3 like models such as Meta’s Llama expanded training scope to
- Arxiv research papers (92GB).
- StackExchange’s code-related Q&As (78 GB).
- GPT-3 paper authors did not share the training dataset.
*Sources:
GPT architecture
- GPT was originally introduced in the paper “Improving Language Understanding by Generative Pre-Training” (https://mng.bz/x2qg) by Radford et al. from OpenAI.
- GPT-3 is a scaled-up version of this model that has more parameters and was trained on a larger dataset.
- In addition, the original model offered in ChatGPT was created by fine-tuning GPT-3 on a large instruction dataset using a method from OpenAI’s InstructGPT paper (https://arxiv.org/abs/2203.02155).
GPT-3 has 96 transformer layers and 175 billion parameters†.
*Sources:
GPT-3 pre-training cost
Estimated to be around $4.5 million in terms of cloud computing credits‡.
Sources: