- Source: YouTube, [LinkedIn](https://www.linkedin.com/posts/danielhanchen_full-workshop-reinforcement-learning-kernels-activity-7353056071583748096-Srg_?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAcOLFMBUn1o8NEoEvAqJrA0ZzVgH3csPQ0, Google Slides, Unsloth, Google Slides
- Speaker: Daniel Han, Unsloth (LinkedIn)
- Additional Resources: Unsloth - Reinforcement Learning (RL) Guide
Presentation
Llama 1 Models A very useful insight form original Llama 1 paper1, and is trained with 1.4T tokens (which is lower as 2025 standards)
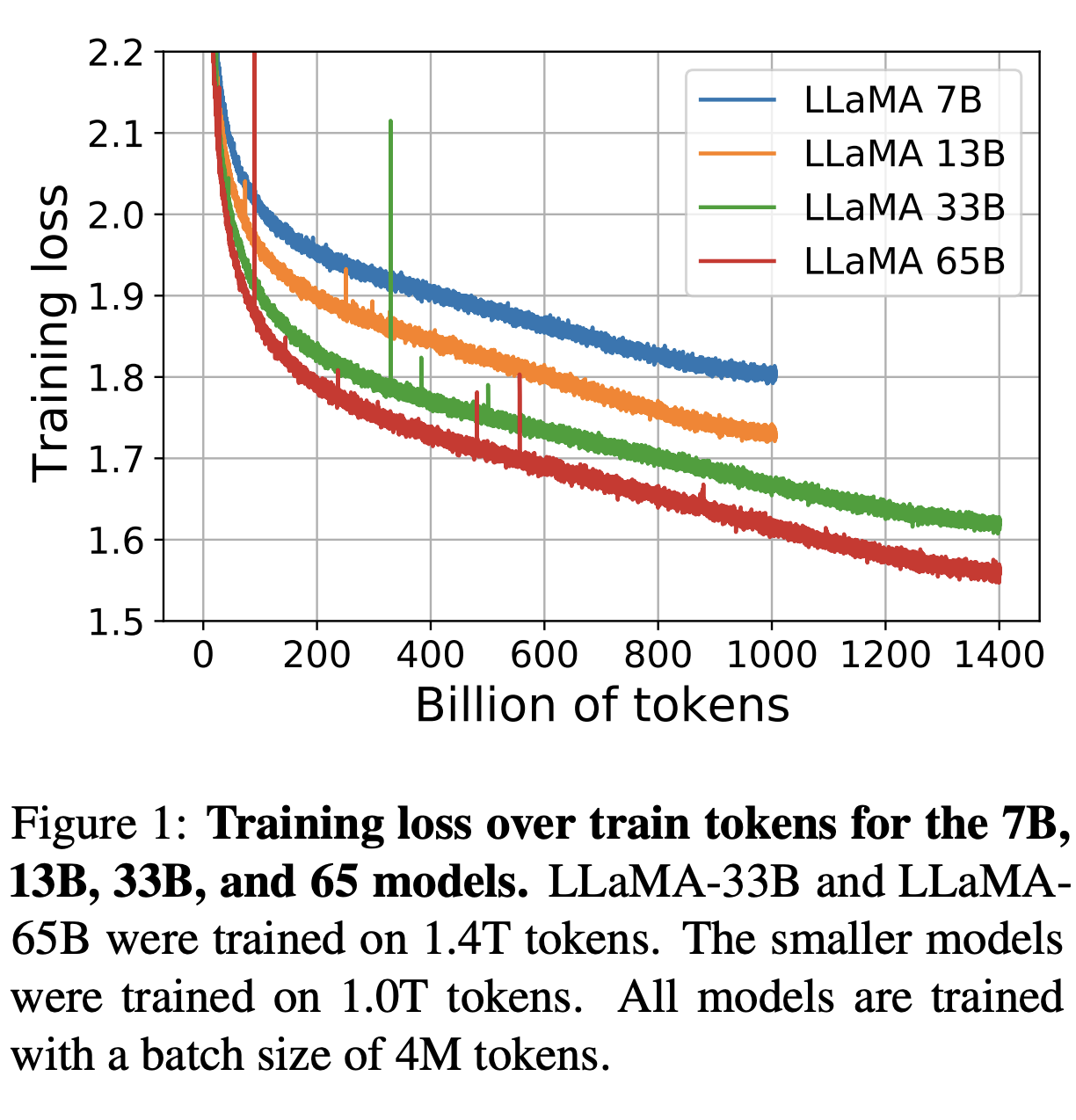
Figure: Llama pre-training data - Training loss going down with more training data and bigger models.
In the figure below, we can see that the slope of open-source model is more dramatic than close-source model. In terms of MMLU (5-shot), we can see that open-source models have reached close to closed source (e.g., Llama 3.1 405B vs. GPT-4).
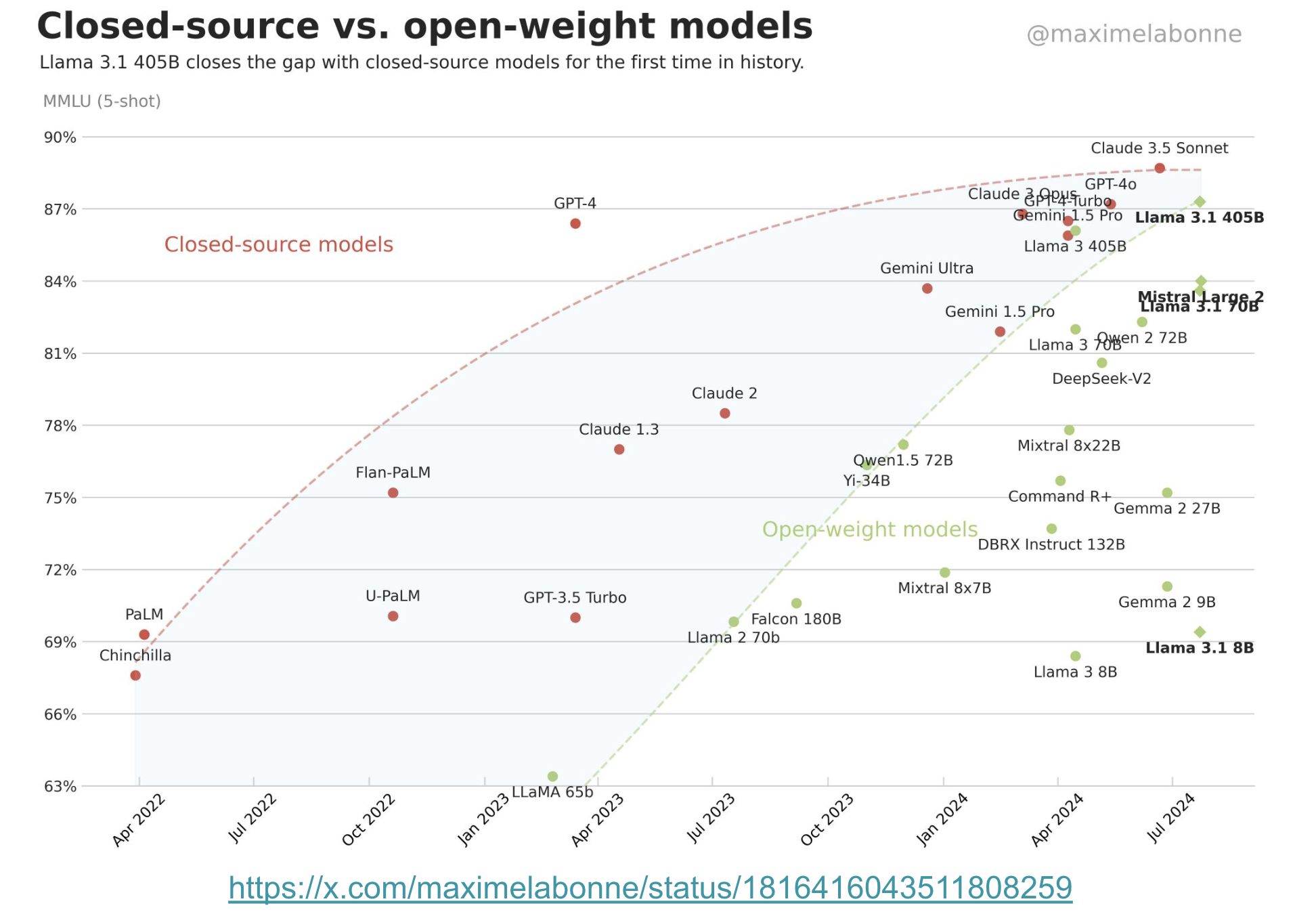 Tweet posted on 2025-Jul in Twitter by Maxime.
Tweet posted on 2025-Jul in Twitter by Maxime.
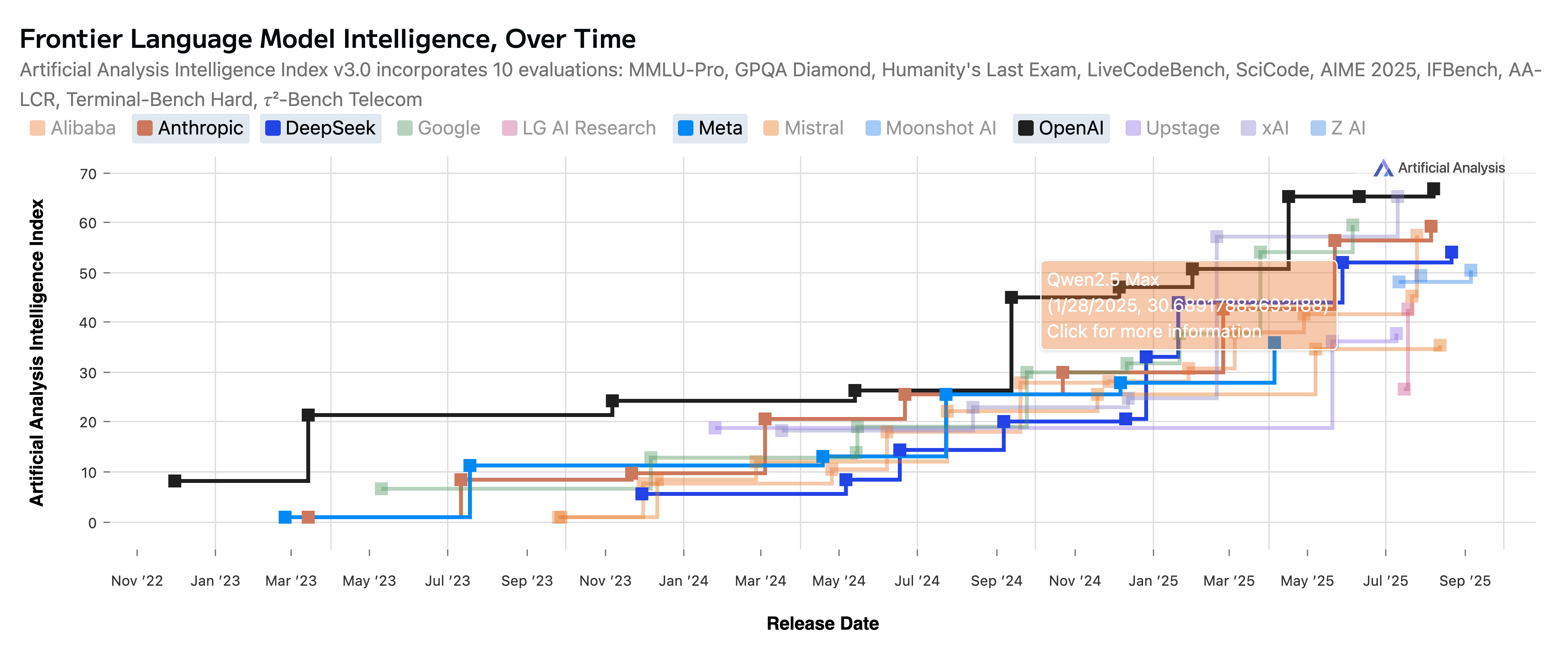
Additionally, we can find model performance comparison over time in other platforms as well:
- https://artificialanalysis.ai/#frontier-language-model-intelligence-over-time
- https://openlm.ai/chatbot-arena/
- https://lmarena.ai/leaderboard
Around Sep 2024, open-source and closed-source models converged in terms of MMLU accuracy, and suddenly, with launch of OpenAI’s o1-preview, the model performance and capability (reasoning, long reasoning traces) shot up. For 4 months, open-source community stalled. Then, suddenly, in Jan 2025 DeeSeek R1 came, and changed the entire world’s perspective that open-source models can indeed perform as good as close-source ones.
Even before ChatGPT launch in Dec 2022, LLMs existed, but the pre-trained base models were terrible in performance. However, ChatGPT showed that we can make the LLMs very useful with
- good data
- good instructions
- good answers
- good SFT
- good RL
Open-source always try to catch up to close-source models.
Two huge jumps of open-source models
- SFT, RLHF jump
- RL jump
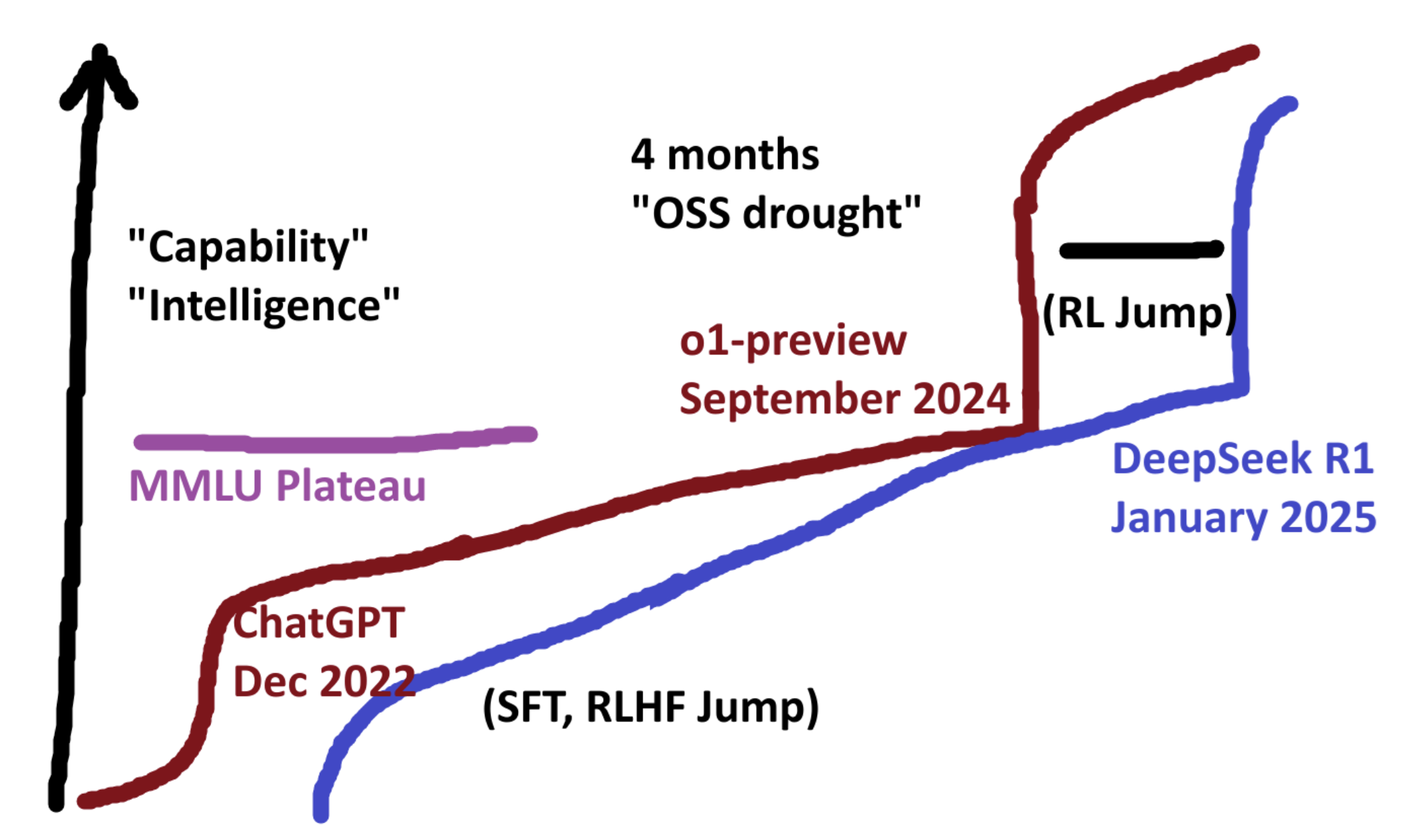
What's the next jump?
We don’t know yet!
Yann LeCun's Analogy
- Pre-training is the “cake”,
- SFT is the “icing”,
- Reinforcement Learning is the “cherry on top”.
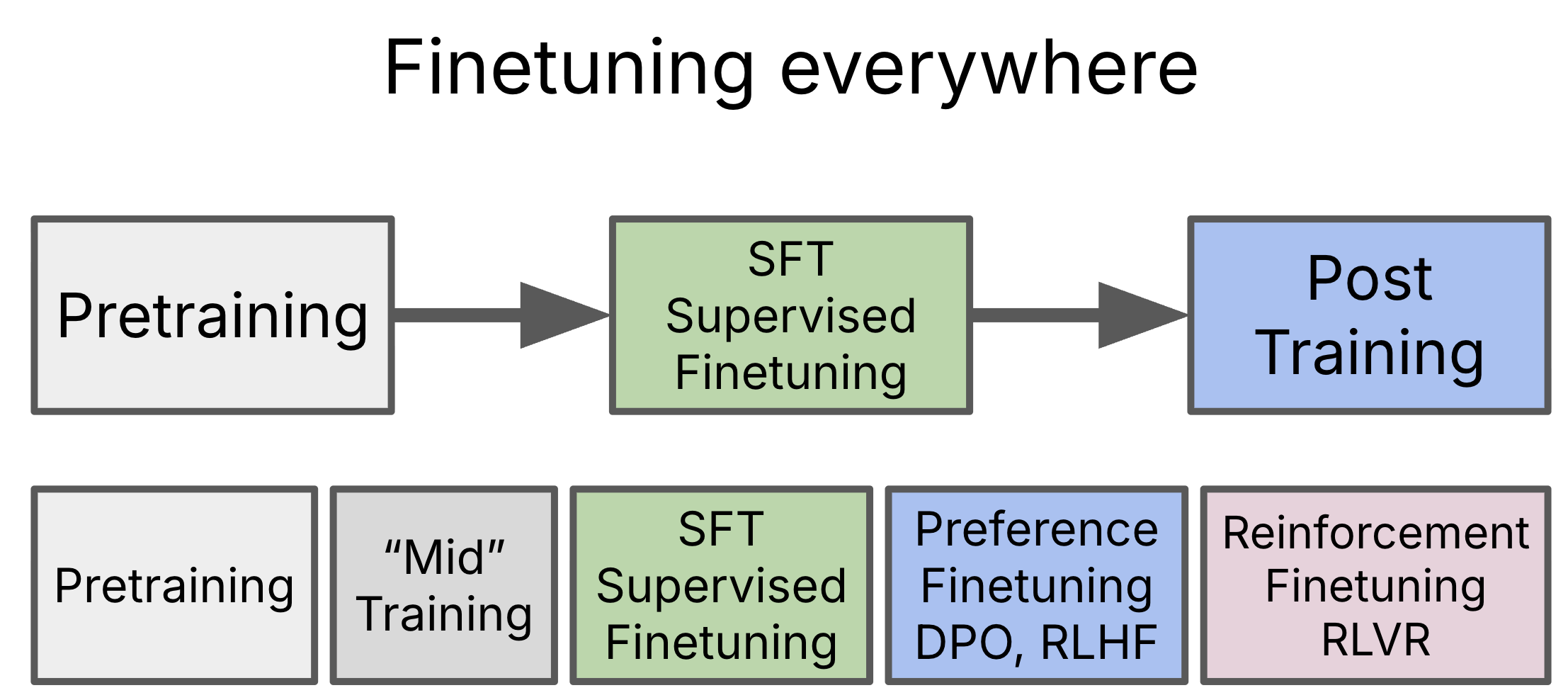
Training Phases
In the past
- Pretraining
- SFT (e.g., Instruction fine-tuning)
- Post Training
Recently,
- Pretraining - Predict the next word
- “Mid” Training - High quality data, long context extension, etc.
- SFT
- Preference Finetuning (DPO, RLHF)
- Reinforcement Finetuning (RLVR)
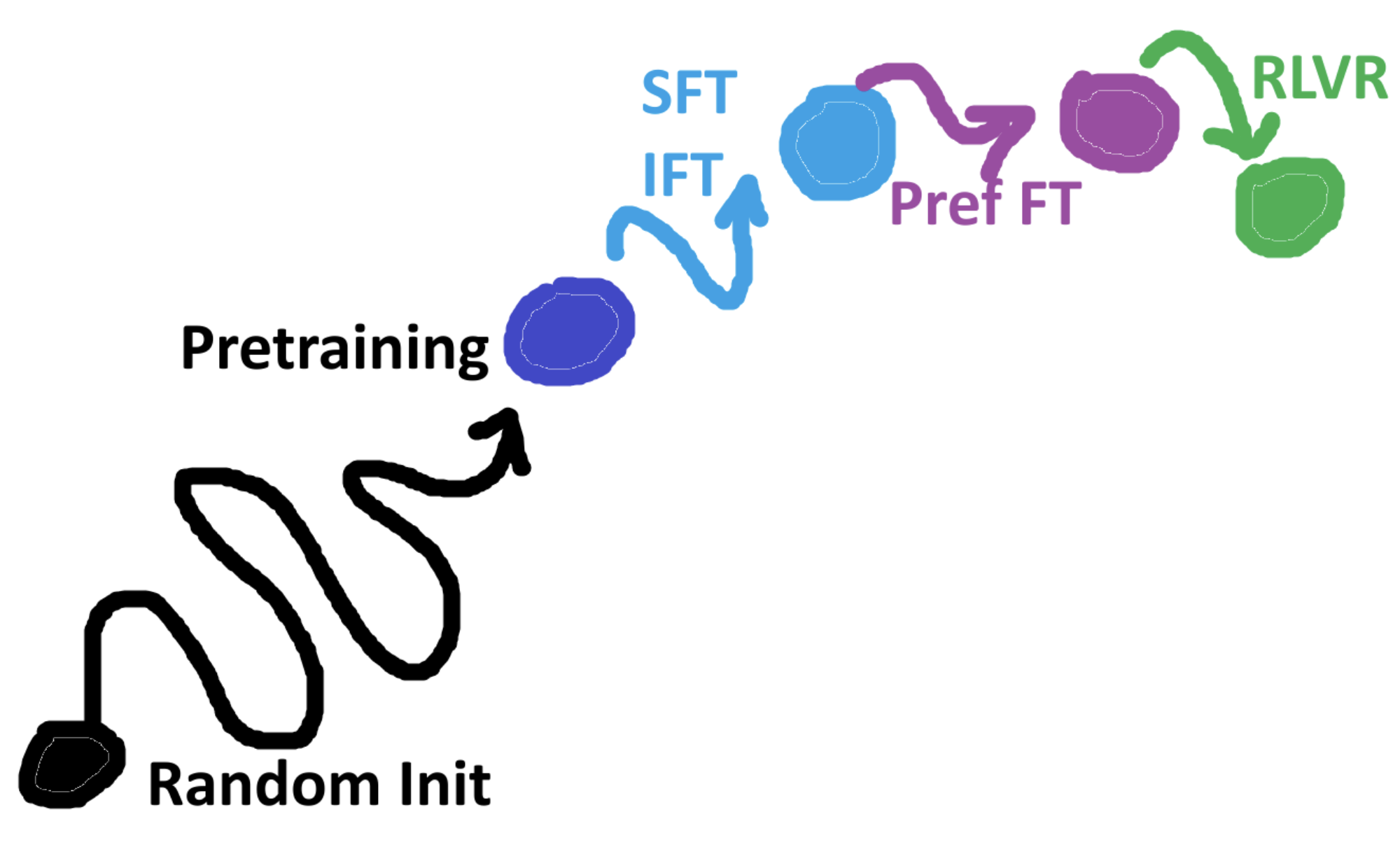
How do we get to our final model? 0. Random init
- Pretraining
- SFT (IFT) - Not much data for SFT
- PrefFT
- RLVR - e.g., gpt o3, o1 models
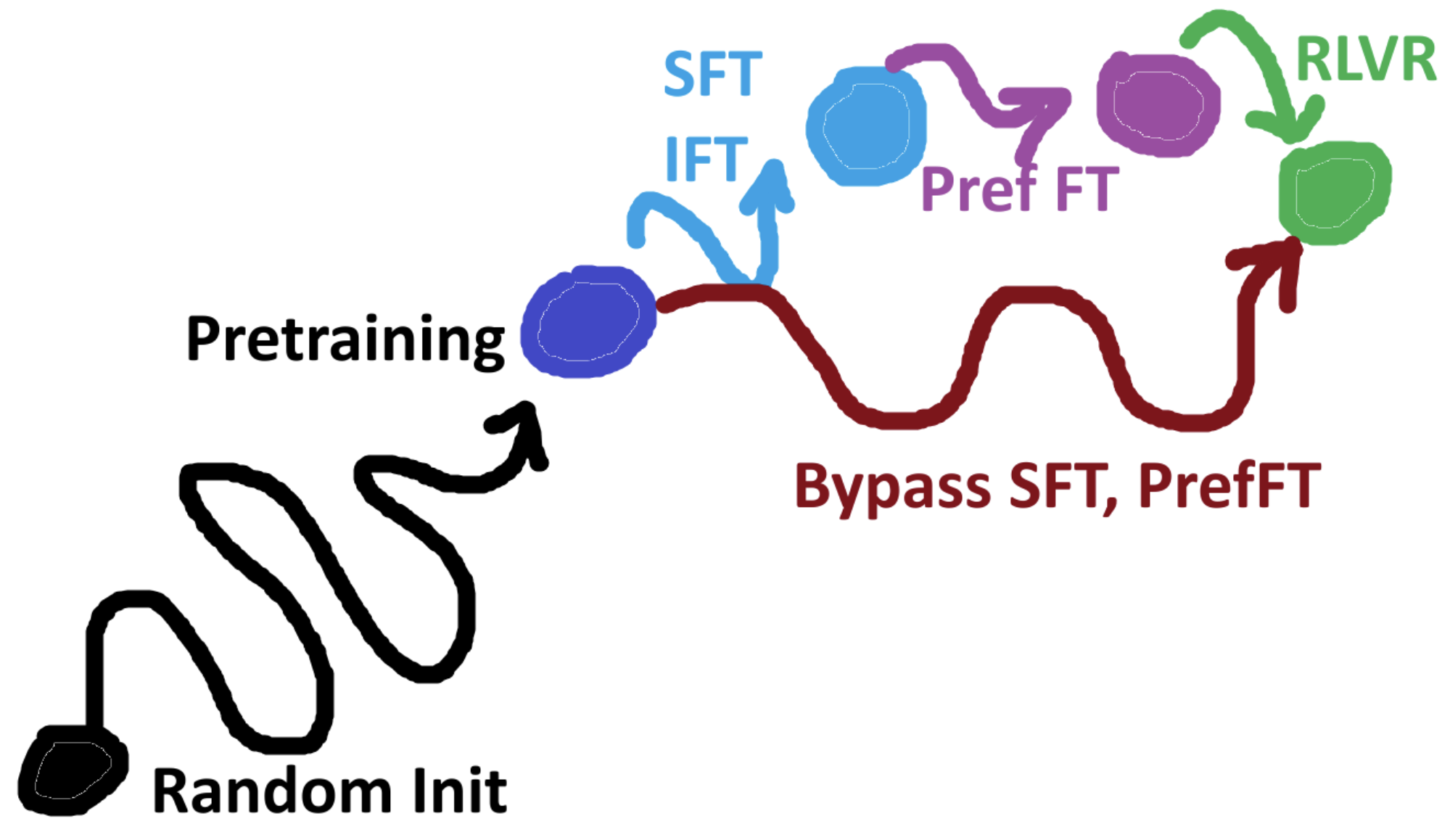
New Paradigm: Bypass SFT an PrefFT
Deepseek R1 has demonstrated this.
Hands-on
- Github code: prasanth-ntu/qwen3_-4b-grpo.ipynb
- Note: Open in Colab for free GPU access