Key resources:
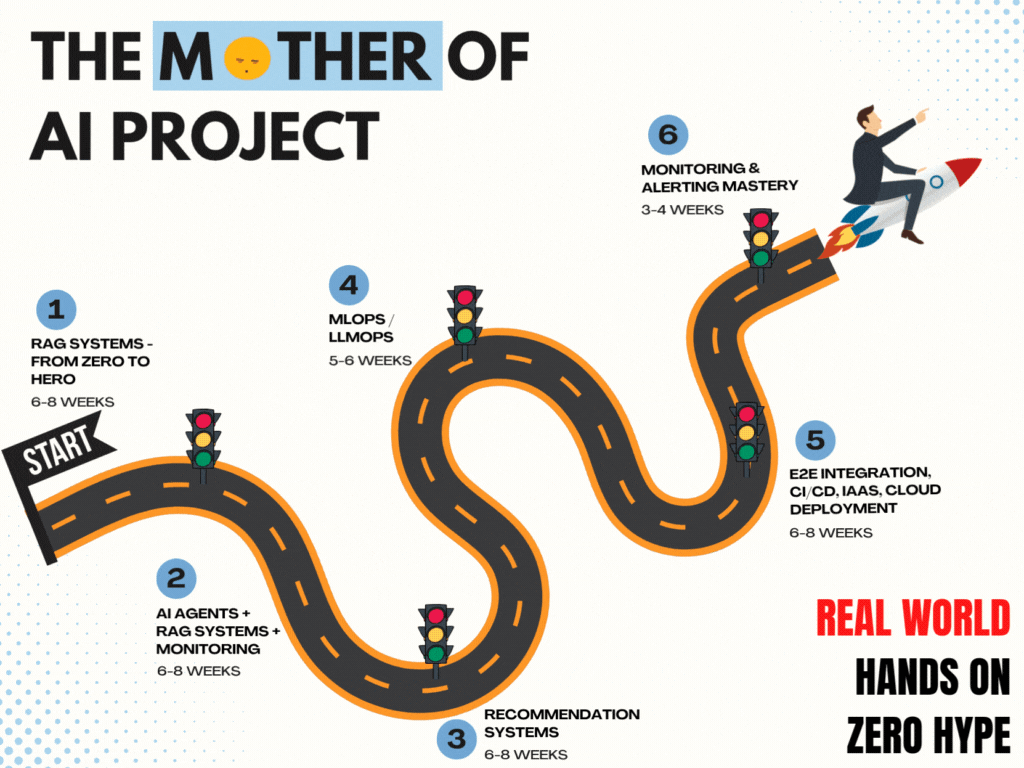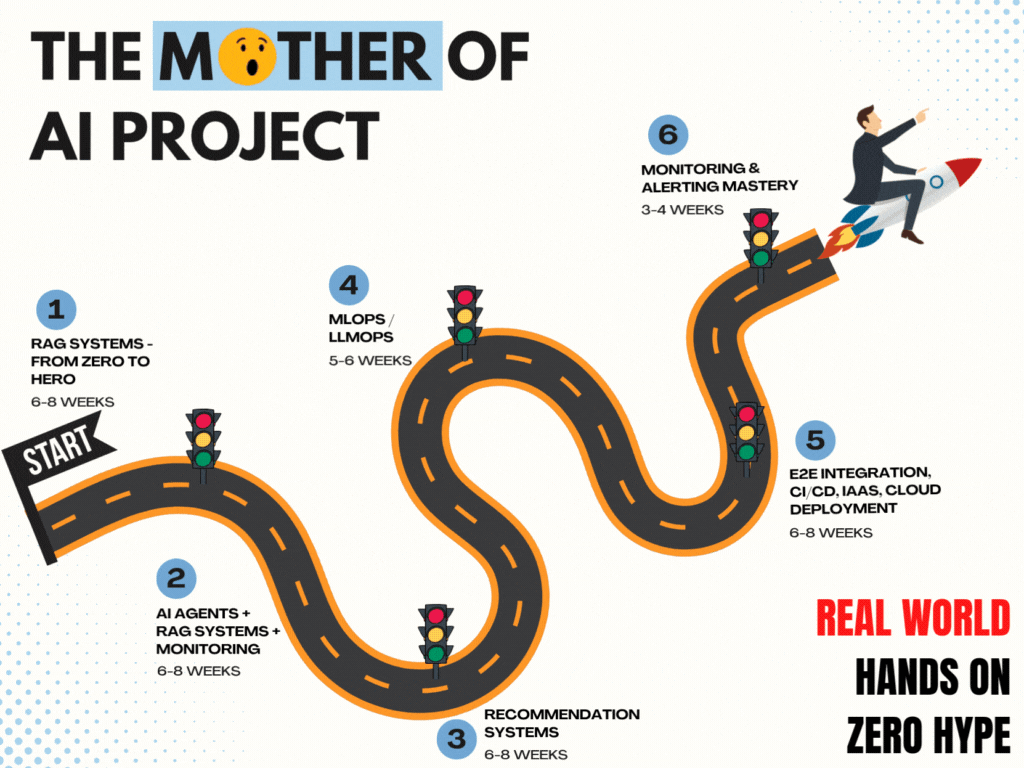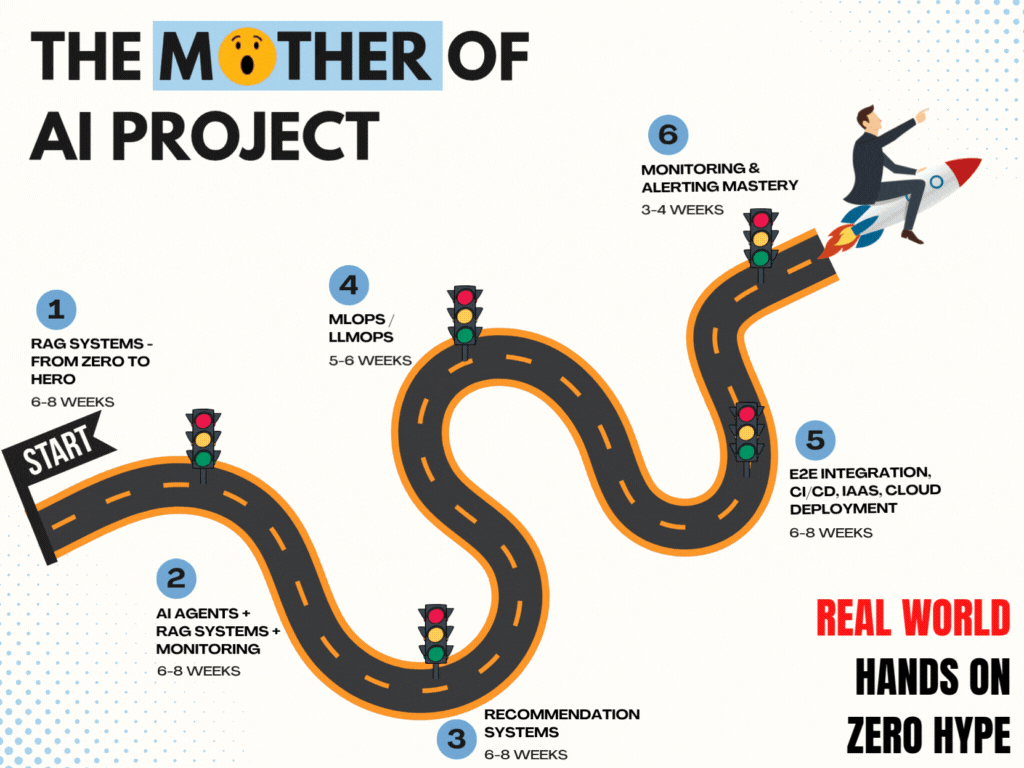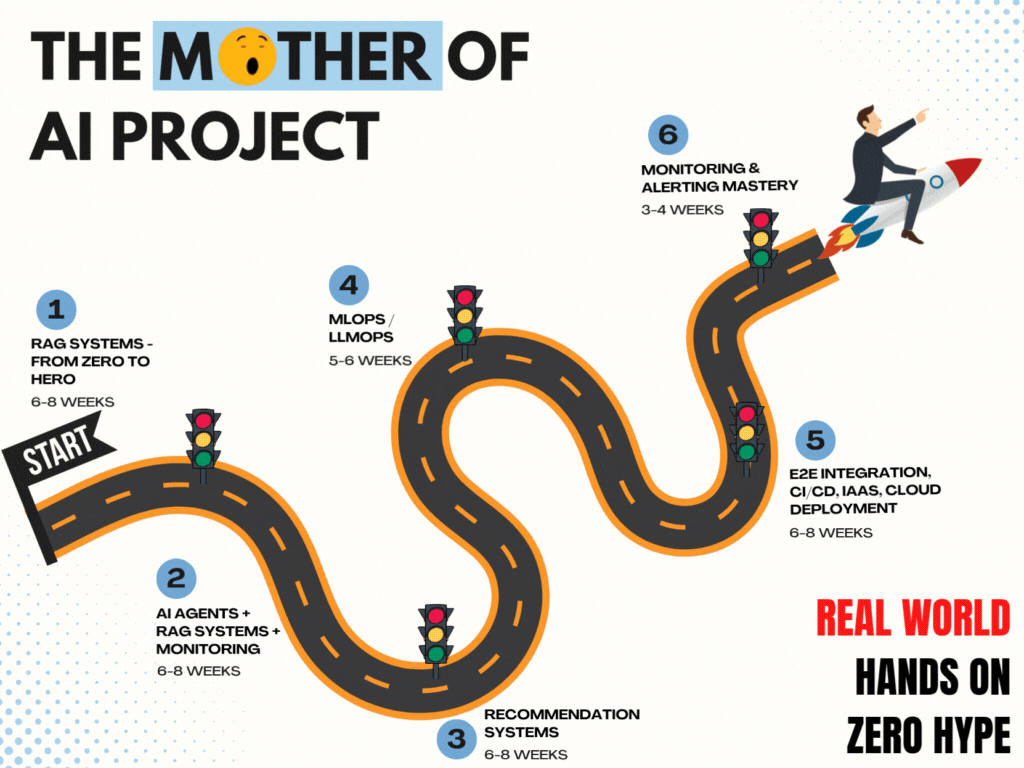
The Project Phases
- Phase 1: RAG Systems: Zero to Hero
- Phase 2: Ai Agents + Tool Use + Monitoring
- Phase 3: Recommendation system
- Phase 4: MLOps + LLMOps
- Phase 5: Ful App Integration + Cloud Deployment
- Phase 6: Monitoring + Alerting Mastery
Phase 1: Build Your Own AI Research Assistant
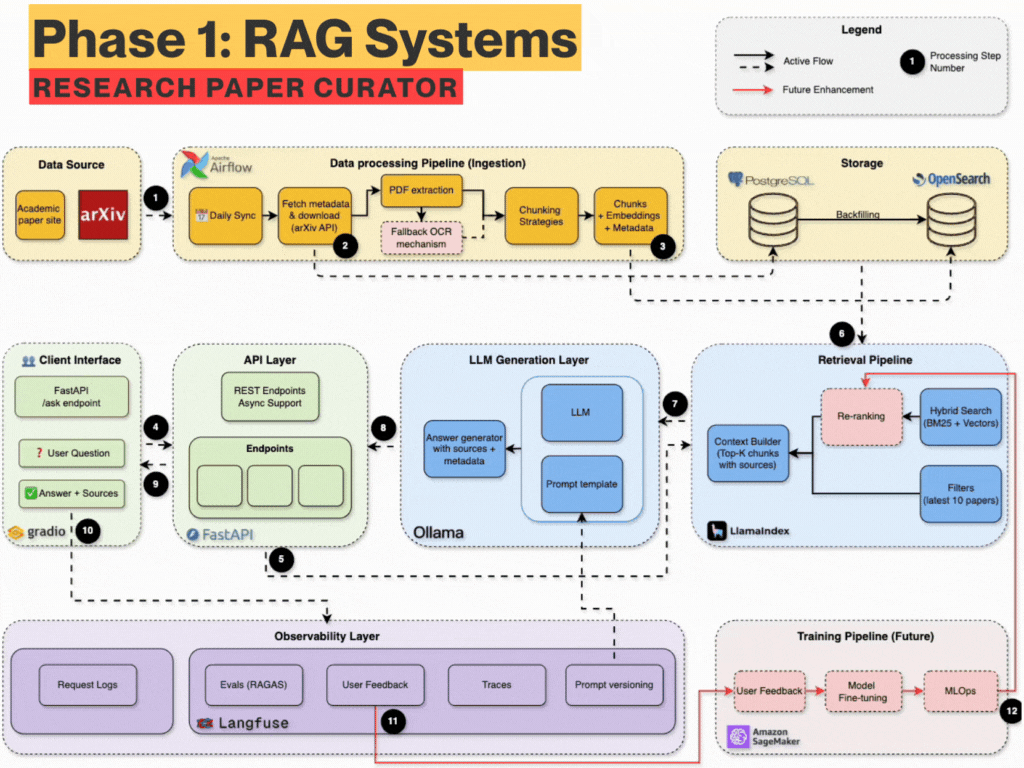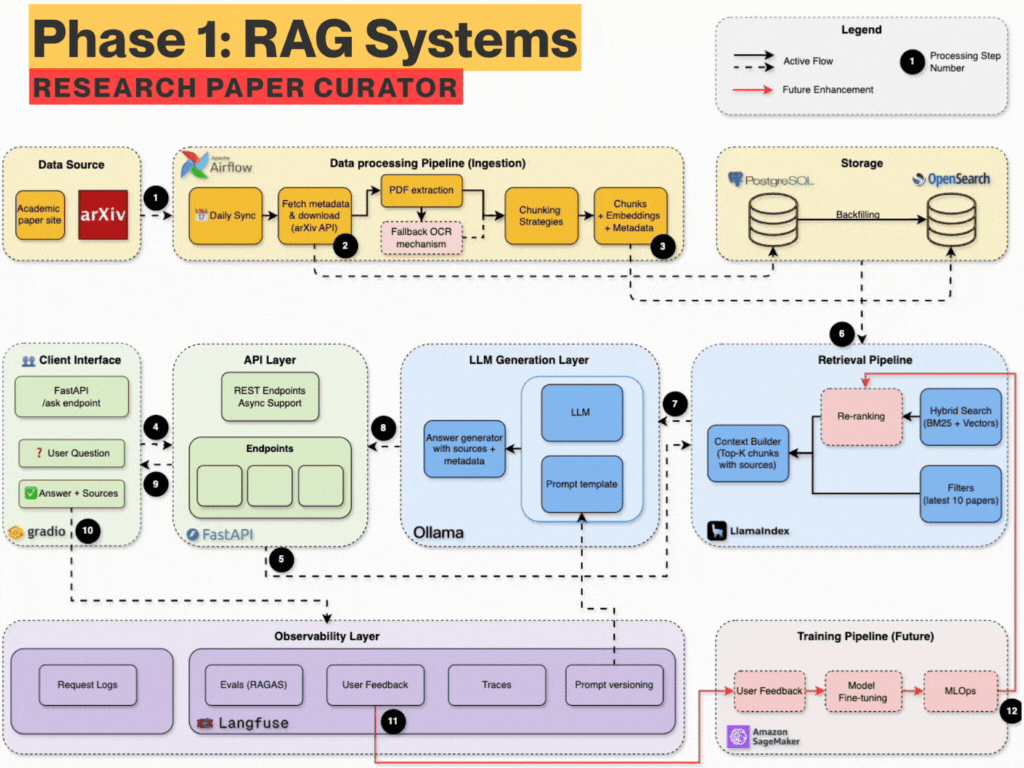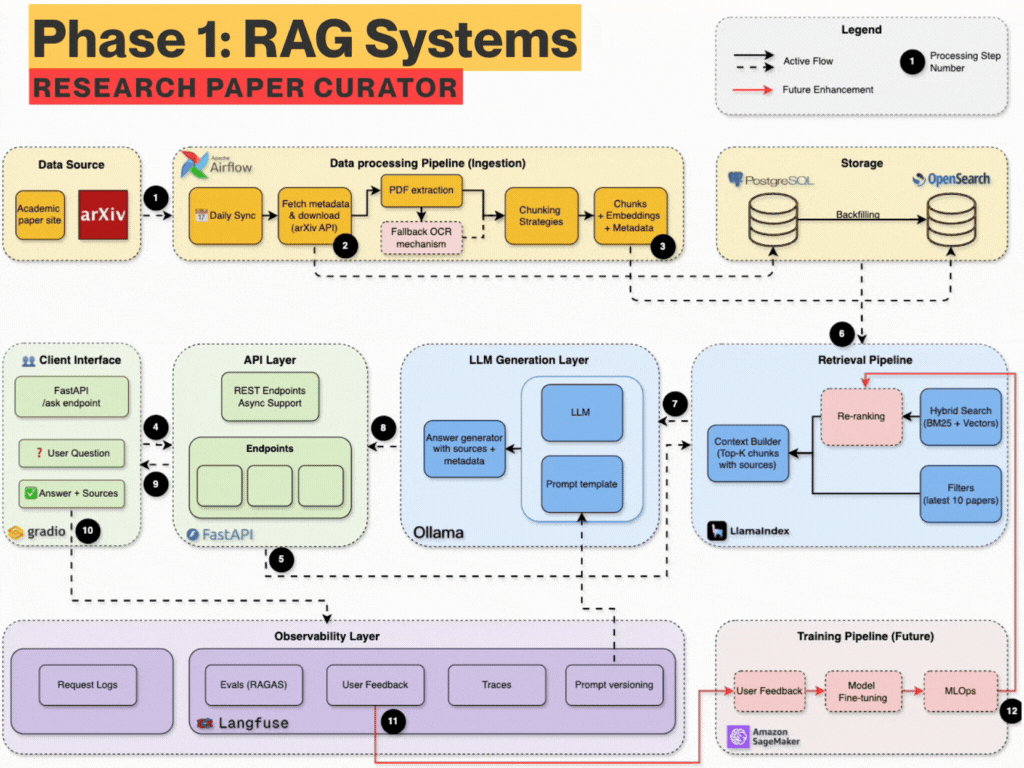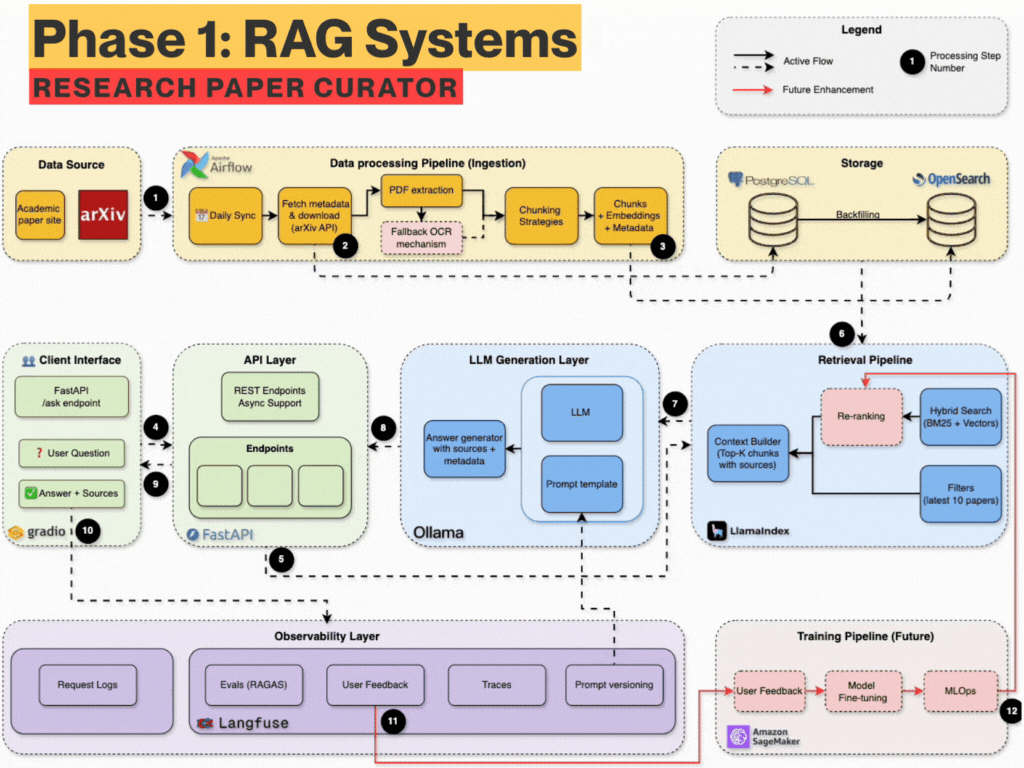
The 6-Week Learning Plan
- Week 1: Infrastructure & API setup
- Week 3: Ingestion Pipeline
- Week 3: Search infrastructure
- Week 4: Chunking + retrieval evaluation
- Week 5: Full RAG system + prompts
- Week 6: Observability + Versioning
Week 1: The Infrastructure That Powers RAG Systems
Substack link
The gap between AI tutorials and production reality isn't the algorithms - it's the infrastructure.
For production use case, we need to make sure our systems have:
- Robust Infrastructure - Services that don’t crash under load
- Clean Architecture - Code that teams can maintain and extend
- Observability - Monitoring that tells you what’s actually happening
- Automation - Pipelines that run without human intervent

Appendix
Git commands
Add the original repository as a remote, fetch tags, and create branches from them:
$ git remote add upstream https://github.com/jamwithai/arxiv-paper-curator.git 2>&1 || echo "Remote may already exist"$ git fetch upstream --tags
From https://github.com/jamwithai/arxiv-paper-curator
* [new branch] feature/deepseek-ocr-integration -> upstream/feature/deepseek-ocr-integration
* [new branch] main -> upstream/main
* [new tag] week1.0 -> week1.0
* [new tag] week2.0 -> week2.0
* [new tag] week3.0 -> week3.0
* [new tag] week4.0 -> week4.0
* [new tag] week5.0 -> week5.0
* [new tag] week6.0 -> week6.0
* [new tag] week7.0 -> week7.0Creating branches from each tag with the my-weekX.0 naming pattern:
$ cd /Users/user/Projects/llm_related/arxiv-paper-curator && git checkout -b
Switched to a new branch 'my-week1.0'$ cd /Users/user/Projects/llm_related/arxiv-paper-curator && git checkout -b my-week2.0 week2.0
Switched to a new branch 'my-week2.0'Repeat the same for other weeks as well.
Switching back to main and verifying all branches were created:
$ git checkout main$ git branch -a | grep -E "(week)"
my-week1.0
my-week2.0
my-week3.0
my-week4.0
my-week5.0
my-week6.0Verifying tags are available:
$ git tag | grep -E "^week[0-9]"
my-week1.0
my-week2.0
my-week3.0
my-week4.0
my-week5.0
my-week6.0
my-week7.0Week 2 - Temporary Backup
.env
# Environment Configuration for arXiv Paper Curator
# Copy this file to .env and adjust values as needed
# Application Settings
APP_VERSION=0.1.0
DEBUG=true
ENVIRONMENT=development
SERVICE_NAME=rag-api
# PostgreSQL Database Configuration
POSTGRES_DATABASE_URL=postgresql://rag_user:rag_password@localhost:5432/rag_db
POSTGRES_ECHO_SQL=false
POSTGRES_POOL_SIZE=20
POSTGRES_MAX_OVERFLOW=0
# OpenSearch Configuration
OPENSEARCH_HOST=http://localhost:9200
# Ollama LLM Configuration
OLLAMA_HOST=http://localhost:11434
OLLAMA_MODELS=llama3.2:1b
OLLAMA_DEFAULT_MODEL=llama3.2:1b
OLLAMA_TIMEOUT=300
# arXiv API Configuration
ARXIV__BASE_URL=https://export.arxiv.org/api/query
ARXIV__PDF_CACHE_DIR=./data/arxiv_pdfs
ARXIV__RATE_LIMIT_DELAY=3.0
ARXIV__TIMEOUT_SECONDS=30
ARXIV__MAX_RESULTS=100
ARXIV__SEARCH_CATEGORY=cs.AI
# PDF Parser Configuration (Week 2)
# Limit pages to prevent memory issues with large papers
PDF_PARSER__MAX_PAGES=20
PDF_PARSER__MAX_FILE_SIZE_MB=20
PDF_PARSER__DO_OCR=false # OCR is very slow, disable for speed
PDF_PARSER__DO_TABLE_STRUCTURE=trueairflow/Dockerfile
FROM python:3.12-slim
# Set environment variables
ENV AIRFLOW_HOME=/opt/airflow
ENV AIRFLOW_VERSION=2.10.3
ENV PYTHON_VERSION=3.12
ENV CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
curl \
git \
libpq-dev \
poppler-utils \
tesseract-ocr \
libgl1 \
libglib2.0-0 \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
# Create airflow user with UID/GID 50000 for cross-platform compatibility
RUN groupadd -r -g 50000 airflow && useradd -r -u 50000 -g airflow -d ${AIRFLOW_HOME} -s /bin/bash airflow
# Create airflow directories with proper ownership
RUN mkdir -p ${AIRFLOW_HOME} && \
mkdir -p ${AIRFLOW_HOME}/dags && \
mkdir -p ${AIRFLOW_HOME}/logs && \
mkdir -p ${AIRFLOW_HOME}/plugins && \
chown -R 50000:50000 ${AIRFLOW_HOME} && \
chmod -R 755 ${AIRFLOW_HOME}
# Install Airflow with PostgreSQL support
RUN pip install --no-cache-dir \
"apache-airflow[postgres]==${AIRFLOW_VERSION}" \
--constraint "${CONSTRAINT_URL}" \
psycopg2-binary
# Copy requirements and install project dependencies
COPY requirements-airflow.txt /tmp/requirements-airflow.txt
RUN pip install --no-cache-dir -r /tmp/requirements-airflow.txt
# Copy and set up entrypoint script
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
# Switch to airflow user and set working directory
USER airflow
WORKDIR ${AIRFLOW_HOME}
# Expose port
EXPOSE 8080
CMD ["/entrypoint.sh"]src/config.py
from typing import Any, Dict, List, Union
from pydantic import Field, field_validator, model_validator
from pydantic_settings import BaseSettings, SettingsConfigDict
class DefaultSettings(BaseSettings):
model_config = SettingsConfigDict(
env_file=".env",
extra="ignore",
frozen=True,
env_nested_delimiter="__",
)
@model_validator(mode="before")
@classmethod
def strip_inline_comments(cls, values: Any) -> Any:
"""Strip inline comments from environment variable values."""
if isinstance(values, dict):
cleaned = {}
for key, value in values.items():
if isinstance(value, str) and "#" in value:
# Strip inline comments (anything after #)
cleaned[key] = value.split("#")[0].strip()
else:
cleaned[key] = value
return cleaned
return values
class ArxivSettings(DefaultSettings):
"""arXiv API client settings."""
base_url: str = "https://export.arxiv.org/api/query"
namespaces: dict = Field(
default={
"atom": "http://www.w3.org/2005/Atom",
"opensearch": "http://a9.com/-/spec/opensearch/1.1/",
"arxiv": "http://arxiv.org/schemas/atom",
}
)
pdf_cache_dir: str = "./data/arxiv_pdfs"
rate_limit_delay: float = 3.0 # seconds between requests
timeout_seconds: int = 30
max_results: int = 100
search_category: str = "cs.AI" # Default category to search
class PDFParserSettings(DefaultSettings):
"""PDF parser service settings."""
max_pages: int = 30
max_file_size_mb: int = 20
do_ocr: bool = False
do_table_structure: bool = True
class Settings(DefaultSettings):
"""Application settings."""
app_version: str = "0.1.0"
debug: bool = True
environment: str = "development"
service_name: str = "rag-api"
# PostgreSQL configuration
postgres_database_url: str = "postgresql://rag_user:rag_password@localhost:5432/rag_db"
postgres_echo_sql: bool = False
postgres_pool_size: int = 20
postgres_max_overflow: int = 0
# OpenSearch configuration
opensearch_host: str = "http://localhost:9200"
# Ollama configuration (used in Week 1 notebook)
ollama_host: str = "http://localhost:11434"
ollama_models: Union[str, List[str]] = Field(default="llama3.2:1b")
ollama_default_model: str = "llama3.2:1b"
ollama_timeout: int = 300 # 5 minutes for LLM operations
# arXiv settings
arxiv: ArxivSettings = Field(default_factory=ArxivSettings)
# PDF parser settings
pdf_parser: PDFParserSettings = Field(default_factory=PDFParserSettings)
@field_validator("ollama_models", mode="before")
@classmethod
def parse_ollama_models(cls, v) -> List[str]:
"""Parse comma-separated string into list of models."""
if isinstance(v, str):
# Handle empty string case - return default
if not v.strip():
return ["llama3.2:1b"]
return [model.strip() for model in v.split(",") if model.strip()]
if isinstance(v, list):
return v
# Fallback to default
return ["llama3.2:1b"]
def get_settings() -> Settings:
"""Get application settings."""
return Settings()